
Detection of Cyberthreats with Computer Vision (Part 3)
Introduction
In the evolving battlefield of cybersecurity, attackers continually refine their strategies to evade detection mechanisms. As explored in our previous article, hash-based and color histogram techniques provide efficient initial screening for near duplicate images, but they fall short of delivering high-confidence threat identification.
Sophisticated cybercriminals exploit this limitation by creating slightly modified visual representations that can slip past basic computer vision techniques.
Part Three of our series delves into advanced content-based near duplicate detection techniques that address these critical gaps. By leveraging object recognition, embedded text comparison and hybrid approaches, we will detect sophisticated visual threats, providing customers with cutting-edge cybersecurity protection.
Reference images
Throughout this article, we will use a set of reference images to demonstrate each detection technique. Image A serves as a baseline, while image B is a fabricated variant with modified text and logo. Image C represents a totally different image. These images will help illustrate how different approaches perform in various scenarios.


Object recognition and local feature detection
In Computer Vision, one of the fundamental challenges is to teach machines to see and understand the world as we do. At the forefront of this pursuit stands SIFT, or Scale-Invariant Feature Transform.
What is SIFT?
Conceived in 1999, SIFT (Scale-Invariant Feature Transform) is a robust algorithm for detecting and describing distinctive features in images, which remain stable even when the image undergoes changes like scaling, rotation, or change in viewpoint.
At its essence, SIFT identifies distinctive “keypoints” in images, which are statistically significant points that maintain their identifiable characteristics across different viewing conditions. The algorithm generates feature descriptors that capture the local image properties, enabling reliable object recognition.
SIFT detects keypoints (which can include corners but also blobs) by analyzing how an image changes at different scales. It does this by progressively blurring the image, and subtracting successive blurred versions, creating a Difference of Gaussians (DoG) that highlights areas with significant contrast changes.
A keypoint is identified when a pixel stands out as a local maximum or minimum compared to its neighbors across multiple scales. To ensure these keypoints are stable, SIFT filters out weak edges and low-contrast points using a refinement step, keeping only strong, distinctive features that remain across transformations.
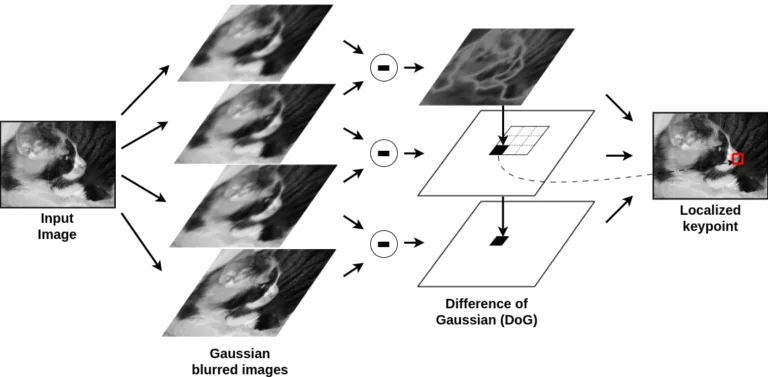
SIFT is powerful but slow because it performs multiple computationally heavy steps: it blurs the image at multiple scales, compares each pixel to 26 neighbors, filters weak keypoints, computes gradient histograms, and generates 128-values descriptors.
All of these steps add up to a massive processing load. This makes SIFT impractical for real-time applications, especially on high-resolution images. While it is precise and robust, its slowness has led to the adoption of faster alternatives like ORB, which trade some accuracy for efficiency.

Introduction to ORB (Oriented FAST and Rotated BRIEF)
ORB (Oriented FAST and Rotated BRIEF) was introduced in “ORB: An efficient alternative to SIFT or SURF” (2011) as a response to the need for a local feature detection and description technique that balances efficiency and robustness.
It combines two key techniques that enhance feature detection and description in images: FAST (Features from Accelerated Segment Test), a high-speed corner detection algorithm, based on intensity variations, and BRIEF (Binary Robust Independent Elementary Features), a binary descriptor for keypoints. However, BRIEF is not rotation-invariant, meaning it is sensitive to image rotations.
Compared to SIFT, FAST detects corners much more quickly. It identifies keypoints at a circle of 16 pixels surrounding the point and compares each one to the center pixel. If a set of contiguous pixels in the circle is significantly brighter or darker than the center, the point is classified as a corner.
To speed things up, FAST first checks a subset of 4 key pixels (instead of all 16) and only evaluates the full circle if necessary, making it much faster than SIFT or even traditional corner detectors like Harris corner detection.
ORB combines these techniques by first using FAST to identify keypoints, then enhancing them with an orientation to make them rotation-invariant. It also incorporates the BRIEF descriptor but improves its rotation-invariant capability.
Image comparison with ORB
Step 1: Preprocessing
Comparing images with ORB consists of several steps, each of which will be illustrated along the way. The process begins with preprocessing the images to make it easier to detect meaningful keypoints. This can be done using various techniques, like converting the image to grayscale then applying an Otsu filter.

Step 2: Keypoint and descriptor calculation
The next step is to calculate the keypoints and descriptors for both images. Since this process can be resource-intensive, the number of extracted keypoints is usually limited (for example, OpenCV defaults to 500). If the image lacks distinct features, such as in the case of a monochromatic or nearly uniform image, the number of detected keypoints may be low.
Step 3: Descriptor matching
Once the keypoints and descriptors are extracted, the next step is to compare the images. A common approach is to use a nearest neighbor search, which involves finding the closest matching descriptor in the second image for each descriptor in the first image.
There are multiple strategies for this search. A brute-force approach, which compares every descriptor pair and has a quadratic complexity, making it computationally expensive. FLANN (Fast Library for Approximate Nearest Neighbors), speeds up the process by using optimized search structures, achieving logarithmic complexity at the cost of slight accuracy loss.
To keep matching feasible, many applications limit the number of extracted keypoints, ensuring a balance between accuracy and computational efficiency, especially in real-time systems.

Step 4: Filtering matches
The last step is to filter the matching descriptors by filtering the pairs with distances higher than a specified threshold. This step helps focus on objects that are truly similar between the two images.
Scoring system for near duplicate detection
In the previous article, we introduced a scoring system ranging from 0 to 1 to estimate the likelihood of an image being a near duplicate. This scoring system enables fine-tuning the detection process by adjusting local and global thresholds to achieve the desired classification accuracy.
To determine whether two images are similar using the ORB approach, we compare the ratio of valid matching descriptors to the total number of available descriptors, using the following steps. First, we identify the number of descriptor pairs that match below a given similarity threshold.
Then, we normalize this count by dividing it by the cardinality of the smaller of the two descriptor sets, ensuring that the score remains within a consistent range. A higher score indicates a greater similarity between the images.
Limitations of ORB
Similarly to previous algorithms, ORB is not exempt from limitations. Its computational requirements might pose challenges for real-time applications, and its efficiency could be compromised when dealing with specific elements, such as embedded text, which is particularly relevant in our context.
Our reference images highlight this limitation: images with dense text tend to contain numerous corners, which can overwhelm ORB’s keypoint detection, leading to less reliable matches and increased processing time.
In the upcoming section, we will delve into an alternative approach to tackle this issue: Optical Character Recognition (OCR).
Embedded text comparison
It is a perpetual cat-and-mouse battle between spammers and editors of security solutions. Spammers continuously innovate, devising new techniques to outwit filters by concealing their unwanted content in inconspicuous corners, such as within images.
Therefore, the ability to extract text from images becomes crucial in countering their endeavors and maintaining the upper hand in this ongoing struggle. Optical Character Recognition (OCR) is a technology that can extract textual information from images.
The most widely used open-source OCR engine is Tesseract (developed by Google), known for its robust multilingual support. Another notable open-source OCR project is EasyOCR, which also offers a deep learning-based approach, and supports over 80 languages, providing a user-friendly and efficient alternative for text recognition tasks.
LLM models, such as Llama Vision, can be used to extract text from images by combining language understanding with visual processing capabilities.
Reference texts
Here is the text extracted from the previous images using the vision model GOT-OCR-2.0. For better readability, we cleaned it up by removing extra spaces.
| Image | Extracted text |
|---|---|
| Image A | Right now, we are offering a rewards program for adults who offer their opinion about THE HOME DEPOT. – Free rewards! (Minimum value: $90) – Free to take the survey. – Provide valuable consumer data. |
| Image B (Image A modified) | Right now, we are offering a rewards program for adults who offer their opinion about ANOTHER BRAND. – Free rewards! (Minimum value: $90) – Free to take the survey. – Provide valuable consumer data. |
| Image C | WELLS FARGO Restore Your Online Access. Our Valued Customer, – This to notify you that we detected irregular activity on your online Banking account. – For your protection, we have limited your account until you verify this activity before you can continue using your account. Click here to complete verification process We are sorry for the inconvenience this may have caused you. Sincerely Wells Fargo, If you have questions, Wells Fargo Online Customer Service is available 24 hours a day, 7 days a week at 1-800-956-4442. |
To illustrate the detection of similar text content, image B, which is a fabricated image, closely resembles image A, with key modifications: the targeted brand and the header have been changed. This practice is commonly observed in real spam campaigns, where attackers often use variations of the same content to target multiple brands.
Text comparison and similarity scoring
There are various approaches to comparing two texts, including string-based methods such as Levenshtein distance, Jaccard index, and cosine similarity, as well as semantic-based techniques like word embeddings and latent semantic analysis.
Structural methods, such as syntactic parsing and tree edit distance, offer yet another perspective. For the sake of clarity, this article will focus on text comparison using Levenshtein distance. This distance calculation measures the minimum number of single-character edits (insertions, deletions or substitutions) required to change one text to the other.
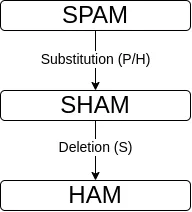
For example, the distance between spam and ham is 2, since it requires a substitution (p->h) and a deletion (s).
Using the Levenshtein distance, here is the calculation employed to compare two string a and b:
max_len = max(len(a), len(b))
text_score(a, b) = (max_len - levenshtein(a, b)) / max_lenThis formula offers a convenient scale from 0 to 1, where 0 signifies entirely dissimilar textual content, and 1 indicates the exact same textual content. The table below presents both the Levenshtein distance and score with Image B.
| Image | Levenshtein distance to Image A | Score distance to Image A |
|---|---|---|
| B (modified content) | 14 | 0.929 |
| Image C | 416 | 0.209 |
Limitations of embedded text comparison
Text-based detection methods face significant limitations. Even Tesseract, a prominent OCR engine, struggles with accuracy, misrecognizing characters and introducing textual noise in our sample images.
Moreover, attackers can exploit sophisticated adversarial techniques, as demonstrated in research like “Fooling OCR Systems with Adversarial Text Images”, which deliberately crafts images to mislead character recognition. The method is further constrained by OCR’s computational costs and scalability challenges.
To address these challenges, hybrid approaches emerge as a powerful solution, by combining multiple detection techniques.
Hybrid approach
In this article and the previous one, we detailed a collection of techniques used to detect near duplicate images. Each one of these techniques has strengths and limitations: for example, some may disregard aspects of the images, while others may be efficient but very costly.
The idea behind hybrid approaches is to combine multiple techniques. In other words, it is like blending the strengths (and compensating for weaknesses) of different techniques to create a more powerful solution. The hybrid approach provides several advantages.
One of the primary benefits of hybrid approaches is their enhanced accuracy. The combination of techniques leverages the strengths of each detection method, resulting in significantly fewer false positives. This reduction in misclassifications is crucial for security solutions providers, as false positives can potentially damage their reputation and credibility in the market.
The robustness and adaptability of hybrid approaches represents another significant advantage. By incorporating a diverse set of techniques, these systems demonstrate remarkable resilience to various image manipulations, ensuring that detection capabilities remain effective even when confronted with subtle modifications.
This adaptability extends to evolving attack strategies and evasion techniques, making hybrid approaches particularly well-suited for today’s dynamic threat landscape.
Efficiency is another key advantage of hybrid approaches. While some techniques are computationally intensive but highly effective, others are faster but may sacrifice some accuracy. This approach allows us to build a strategic workflow that optimizes computational efficiency. For instance, lightweight techniques can be used for initial filtering, followed by more resource-intensive methods for in-depth analysis of suspicious cases only.
The flexibility of hybrid approaches extends to combination strategies. We can employ various mathematical and decision-making methods, including Pareto rules, majority voting, and hierarchical algorithm selection. These strategies allow for nuanced result aggregation, enabling a more sophisticated and reliable image detection process.
While hybrid approaches also have disadvantages (manual parameter tuning, complexity, overhead, …), overall, well-designed and properly configured hybrid approaches can offer a powerful solution to the challenges of near duplicate image detection.
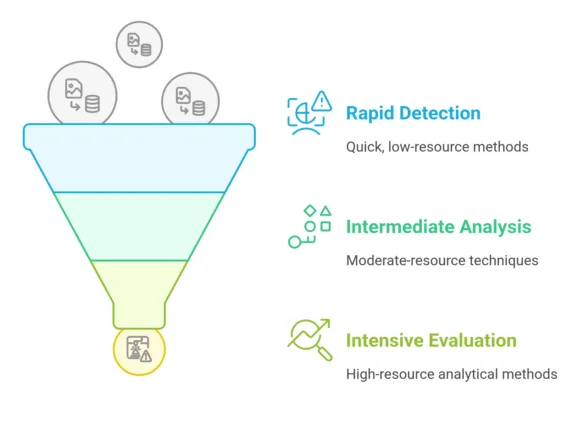
Our Reverse Image Search system leverages hybrid detection profiles, strategically tailored to address specific threat types. Each profile comprises a curated series of detection methods, complemented by aggregation techniques and precise thresholds for threat identification.

To optimize computational efficiency, these detection methods are implemented using a funnel approach, prioritizing rapid, less-intensive techniques before progressively engaging in more resource-demanding analytical methods.
Conclusion
In this article, we have explored advanced techniques for detecting near duplicate images, highlighting the power of hybrid approaches in cybersecurity. By combining methods like ORB, OCR, and strategic detection workflows, we have demonstrated a sophisticated approach to identifying and mitigating visual threats.
Our next article will dive deep into experiments with the Reverse Image Search system, showcasing its real-world performance. Also, we will explore the integration of multimodal LLM models to advance our near duplicate image detection capabilities. By leveraging state-of-the-art machine learning techniques, we aim to perfect our capabilities in visual threat detection through innovative approaches.

