
Erkennung von Cyber-Bedrohungen mit Computer Vision (Teil 3)
Einführung
Auf dem sich ständig weiterentwickelnden Schlachtfeld der Cybersicherheit verfeinern Angreifer kontinuierlich ihre Strategien, um Erkennungsmechanismen zu umgehen. Wie in unserem vorherigen Artikel erläutert, bieten Hash-basierte und Farbhistogramm-Techniken eine effiziente Erstprüfung für nahezu identische Bilder, reichen jedoch nicht aus, um Bedrohungen mit hoher Zuverlässigkeit zu identifizieren. Versierte Cyberkriminelle nutzen diese Einschränkung aus, indem sie leicht modifizierte visuelle Darstellungen erstellen, die grundlegende Computer-Vision-Techniken umgehen können.
Teil 3 unserer Serie befasst sich mit fortschrittlichen inhaltsbasierten Techniken zur Erkennung nahezu identischer Bilder, die diese kritischen Lücken schließen. Durch den Einsatz von Objekterkennung, eingebettetem Textvergleich und hybriden Ansätzen erkennen wir komplexe visuelle Bedrohungen und bieten unseren Kunden modernsten Cybersicherheitsschutz.
Referenzbilder
In diesem Artikel werden wir eine Reihe von Referenzbildern verwenden, um jede Erkennungstechnik zu demonstrieren. Bild A dient als Grundlinie, während Bild B eine gefälschte Variante mit geändertem Text und Logo ist. Bild C stellt ein völlig anderes Bild dar. Anhand dieser Bilder lässt sich veranschaulichen, wie die verschiedenen Ansätze in unterschiedlichen Szenarien funktionieren.


Objekterkennung und Erkennung lokaler Merkmale
Im Bereich der Computer Vision besteht eine der grundlegenden Herausforderungen darin, Maschinen beizubringen, die Welt so zu sehen und zu verstehen, wie wir es tun. An der Spitze dieser Bemühungen steht SIFT (Scale-Invariant Feature Transform).
Was ist SIFT?
SIFT (Scale-Invariant Feature Transform) wurde 1999 entwickelt und ist ein robuster Algorithmus zur Erkennung und Beschreibung charakteristischer Merkmale in Bildern, die auch bei Veränderungen wie Skalierung, Rotation oder Änderung des Blickwinkels stabil bleiben.
Im Wesentlichen identifiziert SIFT charakteristische „Keypoints” in Bildern, bei denen es sich um statistisch signifikante Punkte handelt, die ihre identifizierbaren Eigenschaften unter verschiedenen Betrachtungsbedingungen beibehalten. Der Algorithmus generiert Merkmalsdeskriptoren, die die lokalen Bildeigenschaften erfassen und eine zuverlässige Objekterkennung ermöglichen.
SIFT erkennt Keypoints (die Ecken, aber auch Flecken sein können), indem es analysiert, wie sich ein Bild bei verschiedenen Skalierungen verändert. Dazu wird das Bild schrittweise unscharf gemacht und die aufeinanderfolgenden unscharfen Versionen subtrahiert, wodurch eine Gaußsche Differenz (DoG) entsteht, die Bereiche mit signifikanten Kontraständerungen hervorhebt.
Ein Keypoint wird identifiziert, wenn ein Pixel im Vergleich zu seinen Nachbarn über mehrere Maßstäbe hinweg als lokales Maximum oder Minimum hervorsticht. Um sicherzustellen, dass diese Keypoints stabil sind, filtert SIFT in einem Verfeinerungsschritt schwache Kanten und kontrastarme Punkte heraus und behält nur starke, charakteristische Merkmale bei, die über Transformationen hinweg erhalten bleiben.
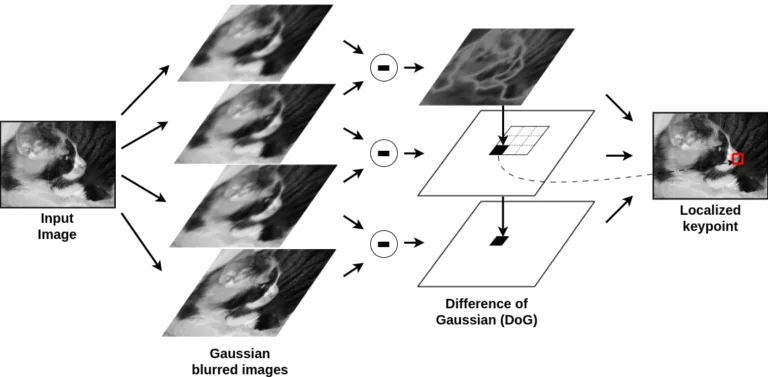
SIFT ist leistungsfähig, aber langsam, weil es mehrere rechenintensive Schritte durchführt: Es verwischt das Bild in mehreren Maßstäben, vergleicht jedes Pixel mit 26 Nachbarn, filtert schwache Keypoints, berechnet Gradientenhistogramme und erzeugt Deskriptoren mit 128 Werten.
All diese Schritte summieren sich zu einer enormen Verarbeitungslast. Dies macht SIFT für Echtzeitanwendungen unpraktisch, insbesondere bei hochauflösenden Bildern. SIFT ist zwar präzise und robust, aber seine Langsamkeit hat dazu geführt, dass schnellere Alternativen wie ORB eingesetzt werden, die einen Teil der Genauigkeit zugunsten von mehr Effizienz einbüßen..

Einblicke in ORB (Oriented FAST & Rotated BRIEF)
ORB (Oriented FAST and Rotated BRIEF) wurde in „ORB: An efficient alternative to SIFT or SURF” (2011) als Antwort auf den Bedarf an einer Technik zur lokalen Merkmalserkennung und -beschreibung eingeführt, die Effizienz und Robustheit in Einklang bringt.
Es kombiniert zwei Schlüsseltechniken, die die Erkennung und Beschreibung von Merkmalen in Bildern verbessern: FAST („Features from Accelerated Segment Test“), einen schnellen Algorithmus zur Eckenerkennung, der auf Intensitätsschwankungen basiert, und BRIEF (Binary Robust Independent Elementary Features), einen binären Deskriptor für Keypoints. BRIEF ist jedoch nicht rotationsinvariant, d. h. es reagiert empfindlich auf Bilddrehungen.
Im Vergleich zu SIFT erkennt FAST Ecken wesentlich schneller. Es identifiziert Keypoints in einem Kreis von 16 Pixeln um den Punkt herum und vergleicht jeden einzelnen mit dem Pixel in der Mitte. Wenn eine Gruppe zusammenhängender Pixel im Kreis deutlich heller oder dunkler als der Mittelpunkt ist, wird der Punkt als Ecke klassifiziert.
Um den Vorgang zu beschleunigen, überprüft FAST zunächst eine Teilmenge von 4 Schlüsselpixeln (anstelle aller 16) und wertet nur bei Bedarf den gesamten Kreis aus, wodurch es wesentlich schneller ist als SIFT oder sogar herkömmliche Eckenerkennungssysteme wie die Harris-Eckenerkennung.
ORB kombiniert diese Techniken, indem es zunächst FAST zur Identifizierung von Keypoints einsetzt und diese dann mit einer Orientierung verbessert, um sie drehungsinvariant zu machen. Es enthält auch den BRIEF-Deskriptor, verbessert aber seine Fähigkeit zur Rotationsinvarianz.
Bildvergleich mit ORB
Schritt 1: Vorverarbeitung
Der Vergleich von Bildern mit ORB umfasst mehrere Schritte, die im Folgenden erläutert werden. Der Prozess beginnt mit der Vorverarbeitung der Bilder, um die Erkennung aussagekräftiger Keypoints zu erleichtern. Dies kann mit verschiedenen Techniken erfolgen, beispielsweise durch Konvertierung des Bildes in Graustufen und anschließende Anwendung eines Otsu-Filters.

Schritt 2: Berechnung von Keypoints und Deskriptoren
Der nächste Schritt besteht darin, die Keypoints und Deskriptoren für beide Bilder zu berechnen. Da dieser Prozess ressourcenintensiv sein kann, ist die Anzahl der extrahierten Keypoints in der Regel begrenzt (z. B. ist OpenCV standardmäßig auf 500 begrenzt). Wenn das Bild keine ausgeprägten Merkmale aufweist, wie z. B. bei einem monochromen oder nahezu einheitlichen Bild, kann die Anzahl der erkannten Keypoints gering sein.
Schritt 3: Abgleich der Deskriptoren
Sobald die Keypoints und Deskriptoren extrahiert sind, werden die Bilder verglichen. Ein gängiger Ansatz ist die Verwendung einer Nearest Neighbor Search (NNS), bei der für jeden Deskriptor im ersten Bild der am besten passende Deskriptor im zweiten Bild gesucht wird.
Für diese Suche gibt es mehrere Strategien. Ein Brute-Force-Ansatz, der jedes Deskriptorenpaar vergleicht und eine quadratische Komplexität aufweist, was ihn rechenintensiv macht. FLANN (Fast Library for Approximate Nearest Neighbors) beschleunigt den Prozess durch die Verwendung optimierter Suchstrukturen und erreicht eine logarithmische Komplexität auf Kosten eines leichten Genauigkeitsverlusts.
Um den Abgleich praktikabel zu halten, begrenzen viele Anwendungen die Anzahl der extrahierten Keypoints, um ein Gleichgewicht zwischen Genauigkeit und Recheneffizienz zu gewährleisten, insbesondere in Echtzeitsystemen.

Schritt 4: Filterung der Treffer
Im letzten Schritt werden die übereinstimmenden Deskriptoren gefiltert, indem die Paare herausgefiltert werden, deren Abstand größer als ein bestimmter Schwellenwert ist. Dieser Schritt hilft, sich auf die Objekte zu konzentrieren, die zwischen den beiden Bildern wirklich ähnlich sind.
Scoring-System zur Erkennung von Beinahe-Duplikaten
Im vorherigen Artikel haben wir ein Bewertungssystem von 0 bis 1 vorgestellt, mit dem die Wahrscheinlichkeit geschätzt werden kann, dass ein Bild ein nahezu identisches Duplikat ist. Dieses Bewertungssystem ermöglicht eine Feinabstimmung des Erkennungsprozesses durch Anpassung lokaler und globaler Schwellenwerte, um die gewünschte Klassifizierungsgenauigkeit zu erreichen.
Um mit dem ORB-Ansatz festzustellen, ob zwei Bilder ähnlich sind, vergleichen wir das Verhältnis der gültigen übereinstimmenden Deskriptoren zur Gesamtzahl der verfügbaren Deskriptoren anhand der folgenden Schritte:
- Zunächst ermitteln wir die Anzahl der Deskriptorpaare, die unter einem bestimmten Ähnlichkeitsschwellenwert übereinstimmen.
- Anschließend normalisieren wir diese Zahl, indem wir sie durch die Kardinalität des kleineren der beiden Deskriptorsätze dividieren, um sicherzustellen, dass die Bewertung in einem konsistenten Bereich bleibt. Eine höhere Bewertung weist auf eine größere Ähnlichkeit zwischen den Bildern hin.
Beschränkungen des ORB
Ähnlich wie frühere Algorithmen ist auch ORB nicht frei von Einschränkungen. Seine Rechenanforderungen könnten für Echtzeitanwendungen eine Herausforderung darstellen, und seine Effizienz könnte beim Umgang mit bestimmten Elementen, wie z. B. eingebettetem Text, der in unserem Kontext besonders relevant ist, beeinträchtigt werden.
Unsere Referenzbilder verdeutlichen diese Einschränkung: Bilder mit dichtem Text enthalten in der Regel zahlreiche Ecken, die die ORB-Keypoints überfordern können, was zu weniger zuverlässigen Übereinstimmungen und erhöhter Verarbeitungszeit führt.
Im nächsten Abschnitt werden wir uns mit einem alternativen Ansatz befassen, um dieses Problem zu lösen: Optische Zeichenerkennung (OCR).
Vergleich von eingebettetem Text
Es ist ein ständiger Wettlauf zwischen Spammern und den Entwicklern von Sicherheitslösungen. Spammer entwickeln ständig neue Techniken, um Filter zu überlisten, indem sie unerwünschte Inhalte an unauffälligen Stellen, beispielsweise in Bildern, verstecken.
Daher ist die Fähigkeit, Text aus Bildern zu extrahieren, von entscheidender Bedeutung, um ihren Bemühungen entgegenzuwirken und in diesem andauernden Kampf die Oberhand zu behalten. Die optische Zeichenerkennung (OCR) ist eine Technologie, mit der Textinformationen aus Bildern extrahiert werden können.
Die am weitesten verbreitete Open-Source-OCR-Engine ist Tesseract (entwickelt von Google), die für ihre robuste Mehrsprachenunterstützung bekannt ist. Ein weiteres bemerkenswertes Open-Source-OCR-Projekt ist EasyOCR, das ebenfalls einen Deep-Learning-basierten Ansatz bietet, über 80 Sprachen unterstützt und eine benutzerfreundliche und effiziente Alternative für Texterkennungsaufgaben darstellt.
LLM-Modelle wie Llama Vision können verwendet werden, um Text aus Bildern zu extrahieren, indem sie Sprachverständnis mit visuellen Verarbeitungsfähigkeiten kombinieren.
Referenztexte
Here is the text extracted from the previous images using the vision model GOT-OCR-2.0. For better readability, we cleaned it up by removing extra spaces.
| Image | Extracted text |
|---|---|
| Bild A | Right now, we are offering a rewards program for adults who offer their opinion about THE HOME DEPOT. – Free rewards! (Minimum value: $90) – Free to take the survey. – Provide valuable consumer data. |
| Bild B (Bild A modizifiert) | Right now, we are offering a rewards program for adults who offer their opinion about ANOTHER BRAND. – Free rewards! (Minimum value: $90) – Free to take the survey. – Provide valuable consumer data. |
| Bild C | WELLS FARGO Restore Your Online Access. Our Valued Customer, – This to notify you that we detected irregular activity on your online Banking account. – For your protection, we have limited your account until you verify this activity before you can continue using your account. Click here to complete verification process We are sorry for the inconvenience this may have caused you. Sincerely Wells Fargo, If you have questions, Wells Fargo Online Customer Service is available 24 hours a day, 7 days a week at 1-800-956-4442. |
Um die Erkennung ähnlicher Textinhalte zu veranschaulichen, ähnelt Bild B, das ein gefälschtes Bild ist, stark Bild A, wobei wichtige Änderungen vorgenommen wurden: Die Zielmarke und die Kopfzeile wurden geändert. Diese Vorgehensweise ist häufig in echten Spam-Kampagnen zu beobachten, bei denen Angreifer oft mehrere Marken mit Variationen desselben Inhalts ins Visier nehmen.
Textvergleich und Ähnlichkeitsscoring
Es gibt verschiedene Ansätze zum Vergleich zweier Texte, darunter stringbasierte Methoden wie die Levenshtein-Distanz, der Jaccard-Index und die Kosinusähnlichkeit sowie semantische Techniken wie Wort-Embeddings und latente semantische Analyse.
Strukturelle Methoden wie syntaktische Parsing und Baum-Edit-Distanz bieten eine weitere Perspektive. Aus Gründen der Übersichtlichkeit konzentriert sich dieser Artikel auf den Textvergleich mit der Levenshtein-Distanz. Diese Distanzberechnung misst die minimale Anzahl von Einzelzeichenänderungen (Einfügungen, Löschungen oder Ersetzungen), die erforderlich sind, um einen Text in einen anderen zu ändern.
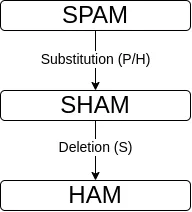
Beispielsweise beträgt die Distanz zwischen „spam” und „ham” 2, da eine Ersetzung (p->h) und eine Löschung (s) erforderlich sind.
Mithilfe des Levenshtein-Abstands werden zwei Strings a und b wie folgt verglichen:
max_len = max(len(a), len(b))
text_score(a, b) = (max_len - levenshtein(a, b)) / max_lenDiese Formel bietet eine bequeme Skala von 0 bis 1, wobei 0 für völlig unterschiedliche Textinhalte steht und 1 für genau denselben Textinhalt. Die folgende Tabelle zeigt sowohl den Levenshtein-Abstand als auch die Punktzahl für Bild B.
| Bild | Levenshthein-Abstand zu Bild A | Punkteabstand zu Bild A |
|---|---|---|
| B (geänderte Inhalte) | 14 | 0.929 |
| C (anderes Bild) | 416 | 0.209 |
Grenzen des eingebetteten Textvergleichs
Textbasierte Erkennungsmethoden unterliegen erheblichen Einschränkungen. Selbst Tesseract, eine bekannte OCR-Engine, hat mit der Genauigkeit zu kämpfen, erkennt Zeichen falsch und fügt in unseren Beispielbildern Textrauschen ein.
Darüber hinaus können Angreifer ausgefeilte gegnerische Techniken ausnutzen, wie in Studien wie „Fooling OCR Systems with Adversarial Text Images” gezeigt wurde, in denen Bilder absichtlich so gestaltet wurden, dass sie die Zeichenerkennung irreführen. Die Methode wird durch die Rechenkosten und Skalierbarkeitsprobleme von OCR weiter eingeschränkt.
Um diese Herausforderungen zu bewältigen, bieten hybride Ansätze eine leistungsstarke Lösung, indem sie mehrere Erkennungstechniken kombinieren.
Hybrider Ansatz
In diesem und dem vorherigen Artikel haben wir eine Reihe von Techniken zur Erkennung von fast identischen Bildern vorgestellt. Jede dieser Techniken hat ihre Stärken und Grenzen: Einige ignorieren beispielsweise bestimmte Aspekte der Bilder, während andere zwar effizient, aber sehr kostspielig sind. Die Idee hinter hybriden Ansätzen ist es, mehrere Techniken zu kombinieren. Mit anderen Worten: Es werden die Stärken verschiedener Techniken gebündelt (und ihre Schwächen ausgeglichen), um eine leistungsfähigere Lösung zu schaffen. Der hybride Ansatz bietet mehrere Vorteile.
Einer der Hauptvorteile von hybriden Ansätzen ist ihre erhöhte Genauigkeit. Durch die Kombination der Techniken werden die Stärken der einzelnen Erkennungsmethoden genutzt, was zu deutlich weniger Fehlalarmen führt. Diese Reduzierung von Fehlklassifikationen ist für Anbieter von Sicherheitslösungen von entscheidender Bedeutung, da Fehlalarme ihren Ruf und ihre Glaubwürdigkeit auf dem Markt schädigen können.
Die Robustheit und Anpassungsfähigkeit hybrider Ansätze stellt einen weiteren wesentlichen Vorteil dar. Durch die Integration verschiedener Techniken zeigen diese Systeme eine bemerkenswerte Widerstandsfähigkeit gegenüber verschiedenen Bildmanipulationen und gewährleisten, dass die Erkennungsfähigkeiten auch bei subtilen Änderungen wirksam bleiben. Diese Anpassungsfähigkeit erstreckt sich auch auf sich weiterentwickelnde Angriffsstrategien und Umgehungstechniken, wodurch hybride Ansätze besonders gut für die dynamische Bedrohungslandschaft von heute geeignet sind.
Effizienz ist ein weiterer wesentlicher Vorteil hybrider Ansätze. Während einige Techniken rechenintensiv, aber sehr effektiv sind, sind andere schneller, aber möglicherweise weniger genau. Dieser Ansatz ermöglicht es uns, einen strategischen Workflow zu entwickeln, der die Recheneffizienz optimiert. So können beispielsweise für die erste Filterung ressourcenschonende Techniken eingesetzt werden, gefolgt von ressourcenintensiveren Methoden für die eingehende Analyse verdächtiger Fälle.
Die Flexibilität hybrider Ansätze erstreckt sich auch auf Kombinationsstrategien. Wir können verschiedene mathematische und Entscheidungsfindungsmethoden einsetzen, darunter Pareto-Regeln, Mehrheitsentscheidungen und hierarchische Algorithmusauswahl. Diese Strategien ermöglichen eine differenzierte Ergebnisaggregation und damit einen ausgefeilteren und zuverlässigeren Bilderkennungsprozess.
Hybride Ansätze haben zwar auch Nachteile (manuelle Parametertuning, Komplexität, Overhead usw.), insgesamt können jedoch gut konzipierte und richtig konfigurierte hybride Ansätze eine leistungsstarke Lösung für die Herausforderungen der Erkennung von fast identischen Bildern bieten.
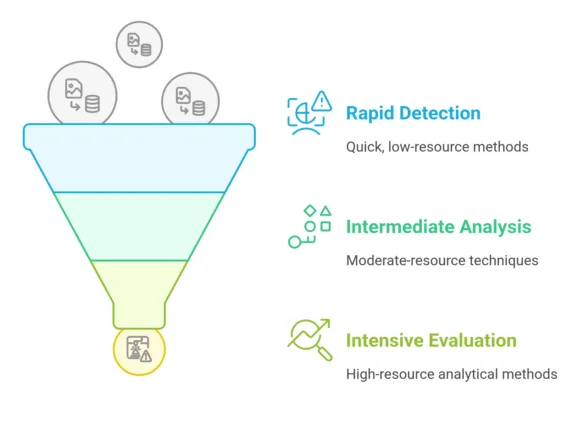
Unser Reverse Image Search System nutzt hybride Erkennungsprofile, die strategisch auf bestimmte Bedrohungsarten zugeschnitten sind. Jedes Profil umfasst eine kuratierte Reihe von Erkennungsmethoden, die durch Aggregationstechniken und präzise Schwellenwerte zur Identifizierung von Bedrohungen ergänzt werden.

Zur Optimierung der Computereffizienz werden diese Erkennungsmethoden nach einem Trichterprinzip implementiert, bei dem schnelle, weniger intensive Techniken Priorität haben, bevor nach und nach ressourcenintensivere Analysemethoden zum Einsatz kommen.
Zusammenfassung
In diesem Artikel haben wir fortschrittliche Techniken zur Erkennung von Beinahe-Duplikaten von Bildern untersucht und dabei die Leistungsfähigkeit hybrider Ansätze im Bereich der Cybersicherheit hervorgehoben. Durch die Kombination von Methoden wie ORB, OCR und strategischen Erkennungsworkflows haben wir einen ausgeklügelten Ansatz zur Identifizierung und Eindämmung visueller Bedrohungen demonstriert.
In unserem nächsten Artikel werden wir uns eingehend mit Experimenten mit dem Reverse Image Search-System befassen und seine Leistung in der Praxis vorstellen. Außerdem werden wir die Integration von multimodalen LLM-Modellen untersuchen, um unsere Fähigkeiten zur Erkennung von Beinahe-Duplikaten zu verbessern. Durch den Einsatz modernster maschineller Lerntechniken wollen wir unsere Fähigkeiten zur Erkennung visueller Bedrohungen durch innovative Ansätze perfektionieren.

