
Détection des cybermenaces par vision par ordinateur (Partie 3)
Introduction
Dans le paysage mouvant de la cybersécurité, les cybercriminels affinent continuellement leurs stratégies pour contourner les mécanismes de détection. Comme nous l’avions exploré dans notre article précédent, les techniques de hachage et d’histogramme de couleur permettent un premier tri efficace pour repérer les images quasi dupliquées. Toutefois, ces méthodes atteignent leurs limites en matière d’identification de menaces sophistiquées avec un haut niveau de confiance.
Les cybercriminels les plus sophistiqués exploitent cette faille en créant des représentations visuelles légèrement modifiées, capables d’échapper aux techniques basiques de vision par ordinateur.
La troisième partie de notre série se penche sur des techniques avancées de détection de contenu quasi dupliqué visant à combler ces lacunes critiques. En tirant parti de la reconnaissance optique de caractères, de la comparaison textuelle et d’approches hybrides, nous serons en mesure de détecter des menaces visuelles sophistiquées, offrant ainsi à nos clients une protection en cybersécurité à la fine pointe de la technologie.
Images de référence
Tout au long de cet article, nous utiliserons un ensemble d’images de référence pour illustrer chaque technique de détection. L’image (A) servira de base comparative, tandis que l’image (B) représentera une variante falsifiée avec du texte et un logo modifiés. L’image (C) sera totalement différente. Ces exemples permettront d’illustrer comment chaque approche se comporte selon divers scénarios.


Reconnaissance d’objets et détection de caractéristiques locales
En vision par ordinateur, l’un des défis fondamentaux est d’apprendre aux machines à voir et à comprendre le monde comme nous le faisons. À l’avant-garde de cette quête se trouve l’algorithme SIFT, ou « transformation de caractéristiques visuelles invariante à l’échelle ».
Qu’est-ce que SIFT ?
Conçu en 1999, SIFT (Scale-Invariant Feature Transform) est un algorithme robuste permettant de détecter et de décrire les caractéristiques distinctives d’une image, lesquelles demeurent stables même lorsque l’image subit des modifications comme un redimensionnement, une rotation ou un changement de perspective.
En son cœur, SIFT identifie des « points clés » (keypoints) dans les images, c’est-à-dire des points statistiquement significatifs, conservant leurs caractéristiques à travers différentes conditions d’observation. L’algorithme génère ensuite des descripteurs de caractéristiques locales qui capturent les propriétés de l’image, permettant ainsi une reconnaissance fiable des objets.
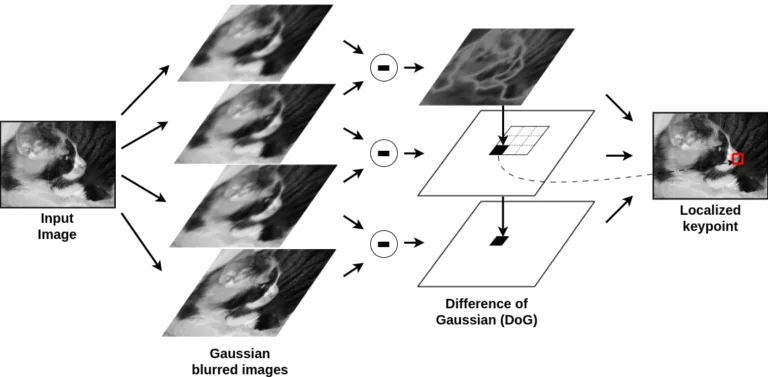
SIFT détecte les points clés (qui peuvent inclure des coins, mais aussi des zones plus diffuses) en analysant la manière dont l’image change à différentes échelles. Cela se fait en floutant progressivement l’image, puis en soustrayant des versions floutées successives, ce qui crée une « différence de gaussiennes » (DoG, Difference of Gaussians), mettant en évidence des zones présentant des variations de contraste importantes.
Un point clé est détecté lorsqu’un pixel se distingue comme un maximum ou un minimum local par rapport à ses voisins à travers plusieurs échelles. Pour s’assurer que ces points clés sont stables, SIFT filtre les contours faibles et les points à faible contraste grâce à une étape de raffinage, ne conservant que les caractéristiques les plus fortes et distinctives malgré les transformations.
SIFT est puissant, mais lent, car il exécute plusieurs étapes computationnelles complexes : il floute l’image à plusieurs échelles, compare chaque pixel à 26 voisins, filtre les points clés faibles, calcule des histogrammes de gradients et génère des descripteurs de 128 valeurs.
Toutes ces étapes représentent une charge de traitement considérable, ce qui rend SIFT peu pratique pour les applications en temps réel, surtout avec des images à haute résolution. Bien qu’il soit précis et robuste, sa lenteur a favorisé l’adoption d’alternatives plus rapides comme ORB, qui échangent une partie de la précision au profit de l’efficacité.

Introduction à ORB (Oriented FAST and Rotated BRIEF)
ORB (Oriented FAST and Rotated BRIEF) a été introduit dans l’article « ORB : An efficient alternative to SIFT or SURF » (2011) en réponse au besoin d’une méthode de détection et de description locale des caractéristiques visuelles, alliant efficacité et robustesse.
Il combine deux techniques clés pour améliorer la détection et la description des caractéristiques dans les images : FAST (Features from Accelerated Segment Test), un algorithme à haute vitesse de détection de coins, basés sur des variations d’intensité, et BRIEF (Binary Robust Independent Elementary Features), un descripteur binaire pour les points clés. Cependant, BRIEF n’est pas invariant à la rotation, ce qui signifie qu’il est sensible aux rotations de l’image.
Comparé à SIFT, l’algorithme FAST détecte les coins beaucoup plus rapidement. Il identifie des points clés sur un cercle de 16 pixels entourant le point central et compare chacun de ces pixels au pixel central. Si un ensemble de pixels contigus dans le cercle est significativement plus clair ou plus foncé que le centre, le point est classé comme un coin.
Pour accélérer le processus, FAST vérifie d’abord un sous-ensemble de 4 pixels clés (au lieu des 16) et n’évalue le cercle complet que si nécessaire, ce qui le rend beaucoup plus rapide que SIFT ou même les détecteurs de coins traditionnels comme le détecteur de Harris.
ORB combine ces techniques en utilisant d’abord FAST pour identifier les points clés, puis en leur attribuant une orientation afin de les rendre invariants à la rotation. Il intègre également le descripteur BRIEF, mais améliore sa capacité d’invariance à la rotation.
Comparaison d’images avec ORB
Étape 1 : Prétraitement
La comparaison d’image avec ORB comprend plusieurs étapes, chacune illustrée ci-dessous. Le processus commence par le prétraitement des images afin de faciliter la détection pertinente des points clés. Cela peut être fait à l’aide de diverses techniques, comme la conversion de l’image en niveaux de gris, suivie de l’application d’un filtre d’Otsu.

Étape 2 : Calcul des points clés et descripteurs
L’étape suivante consiste à calculer les points clés et les descripteurs des deux images. Puisque ce processus peut être exigeant en ressources, le nombre de points clés extraits est généralement limité (par exemple, OpenCV utilise une valeur par défaut de 500). Si l’image manque de caractéristiques distinctives, comme dans le cas d’une image monochrome ou presque uniforme, le nombre de points clés détectés peut être faible.
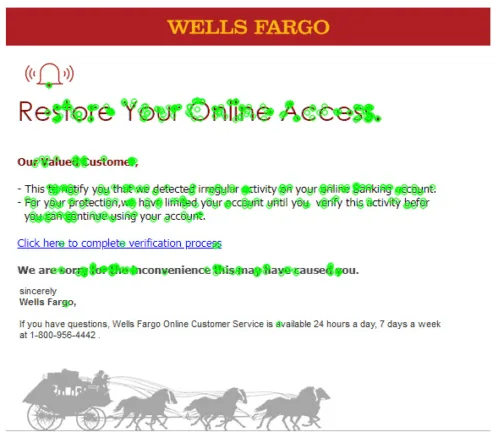
Étape 3 : Appariement des descripteurs
Une fois les points clés et descripteurs extraits, l’étape suivante consiste à comparer les images. Une méthode courante consiste à utiliser une recherche du plus proche voisin, qui consiste à trouver les descripteurs les plus proches dans la deuxième image pour chaque descripteur de la première image.
Il existe plusieurs stratégies pour cette recherche. Une méthode de force brute, qui compare chaque paire de descripteurs, présente une complexité quadratique, ce qui la rend coûteuse sur le plan computationnel. FLANN (Fast Library for Approximate Nearest Neighbors), une bibliothèque rapide conçue pour la recherche de voisin approximatif, permet d’optimiser les structures de recherche, ce qui réduit la complexité à un niveau logarithmique, tout en acceptant une légère perte de précision.
Cela permet un bon compromis entre rapidité et précision, particulièrement utile dans les systèmes en temps réel.

Étape 4 : Filtrage des correspondances
La dernière étape consiste à filtrer les descripteurs correspondants en éliminant les paires dont la distance dépasse un seuil prédéfini. Cette étape permet de se concentrer sur les objets véritablement similaires entre les deux images.
Score de similarité pour la détection d’images quasi dupliquées
Dans l’article précédent, nous avons introduit un score de similarité allant de 0 à 1 pour estimer la probabilité qu’une image soit un doublon quasi dupliqué. Ce score permet d’ajuster le processus de détection en modifiant les seuils locaux et globaux, afin d’atteindre le niveau de précision de classification souhaité.
Pour déterminer si deux images sont similaires à l’aide de l’approche ORB, on compare le ratio de descripteurs correspondants valides au nombre total de descripteurs disponibles, en suivant les étapes suivantes. D’abord, on identifie le nombre de paires de descripteurs qui correspondent à un seuil de similarité donné.
Ensuite, ce nombre est normalisé par rapport au plus petit ensemble de descripteurs des deux images, ce qui garantit que le score reste dans une plage cohérente. Un score plus élevé indique une plus grande similarité entre les images.
Limite de l’approche ORB
Comme d’autres algorithmes, ORB n’est pas exempt de limites. Ses exigences en matière de calcul peuvent poser des défis pour les applications en temps réel, et son efficacité peut être compromise lorsqu’il est confronté à des éléments spécifiques, comme le texte intégré aux images, ce qui est particulièrement pertinent dans notre contexte.
Nos images de référence illustrent bien cette limitation : les images contenant du texte dense tendent à produire un grand nombre de coins, ce qui peut surcharger la détection de points clés d’ORB, entraînant ainsi des correspondances moins fiables et un temps de traitement accru.
Dans la section suivante, nous présenterons une autre approche pour surmonter cette difficulté : la reconnaissance optique de caractères (OCR).
Comparaison de texte intégré
La lutte entre les expéditeurs de spams et les éditeurs de solutions de sécurité est perpétuelle. Les spammeurs innovent sans cesse, développant de nouvelles techniques pour dissimuler leur contenu indésirable dans des endroits peu visibles, comme à l’intérieur d’images.
C’est pourquoi la capacité d’extraire du texte à partir d’images devient essentielle pour contrer leurs efforts tout en maintenant une compréhension claire du contenu. La reconnaissance optique de caractères (OCR en anglais) est une technologie qui permet d’extraire le contenu textuel à partir d’images.
Le moteur d’OCR libre le plus utilisé est Tesseract (développé par Google), reconnu pour sa prise en charge multilingue. Un autre outil libre notable est EasyOCR, qui propose une approche fondée sur l’apprentissage profond et prend en charge plus de 80 langues, offrant ainsi une solution conviviale et efficace pour la reconnaissance de texte.
Des modèles de langage, comme Llama Vision, peuvent également être utilisés pour extraire du texte à partir d’images, en combinant la compréhension linguistique et les capacités de traitement visuel.
Textes de références
Voici le texte extrait des images précédentes à l’aide du modèle de vision GOT-OCR-2.0. Pour en faciliter la lecture, nous l’avons nettoyé en supprimant les espaces superflus :
| Image | Texte extrait |
|---|---|
| Image A | Right now, we are offering a rewards program for adults who offer their opinion about THE HOME DEPOT. – Free rewards! (Minimum value: $90) – Free to take the survey. – Provide valuable consumer data. |
| Image B (version modifiée) | Right now, we are offering a rewards program for adults who offer their opinion about ANOTHER BRAND. – Free rewards! (Minimum value: $90) – Free to take the survey. – Provide valuable consumer data. |
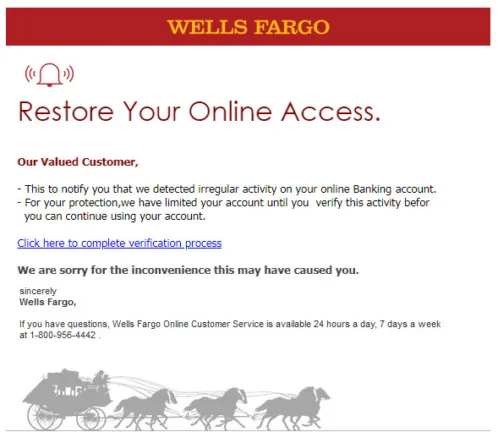
| Image C | WELLS FARGO Restore Your Online Access. Our Valued Customer, – This to notify you that we detected irregular activity on your online Banking account. – For your protection, we have limited your account until you verify this activity before you can continue using your account. Click here to complete verification process We are sorry for the inconvenience this may have caused you. Sincerely Wells Fargo, If you have questions, Wells Fargo Online Customer Service is available 24 hours a day, 7 days a week at 1-800-956-4442. |
Pour illustrer la détection de contenu textuel similaire, l’image B — une image fabriquée — ressemble fortement à l’image A, avec des modifications clés : la marque ciblée et l’entête ont été modifiées. Cette pratique est couramment observée dans les campagnes réelles d’envoi massif de spams, où les attaquants visent souvent plusieurs marques en utilisant des variantes du même contenu.
Comparaison de texte et score de similarité
Il existe plusieurs approches pour comparer deux textes, incluant des méthodes basées sur les chaînes de caractères comme la distance de Levenshtein, l’indice de Jaccard et la similarité cosinus, ainsi que des techniques sémantiques comme les plongements de mots (word embeddings) et l’analyse sémantique latente.
Les méthodes structurelles, telles que l’analyse syntaxique ou la distance d’édition d’arbre, offrent une perspective différente. Dans un souci de clarté, cet article se concentre sur la comparaison textuelle à l’aide de la distance de Levenshtein, qui mesure le nombre minimal de modifications élémentaires (insertions, suppressions ou substitutions de caractères) nécessaires pour transformer un texte en un autre.
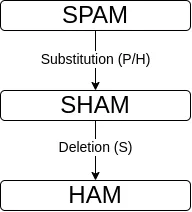
Par exemple, la distance entre SPAM et HAM est de 2, car une substitution (remplacement de P par H) et une suppression (du S) sont nécessaires pour passer de l’un à l’autre.
Voici le calcul utilisé pour comparer deux chaînes de caractères A et B, basé sur la distance de Levenshtein :
max_len = max(len(a), len(b))
text_score(a, b) = (max_len - levenshtein(a, b)) / max_lenCette formule donne un score entre 0 et 1, où 0 signifie un contenu textuel totalement différent, et 1 indique un contenu textuel identique. Le tableau ci-dessous présente la distance de Levenshtein et le résultat de similarité pour l’image B comparée à l’image A.
| Image | Distance de Levenshtein par rapport à l’image A | Résultat de similarité par rapport à l’image A |
|---|---|---|
| B (contenu modifié) | 14 | 0.929 |
| C (image différente) | 416 | 0.209 |
Limites de la comparaison de texte intégré
Les méthodes de détection basées sur le texte présentent des limites importantes. Même Tesseract, un moteur de reconnaissance optique de caractères (OCR) bien établi, rencontre des difficultés à maintenir une précision constante, en raison de la mauvaise reconnaissance de certains caractères et de l’introduction de bruit textuel dans les images analysées.
De plus, les cybercriminels peuvent exploiter des attaques sophistiquées, comme l’a démontré l’article intitulé « Fooling OCR Systems with Adversarial Text Images », dans lequel des images sont délibérément conçues pour tromper les moteurs de reconnaissance de caractères. Ces limites sont accentuées par les coûts computationnels élevés de l’OCR et les enjeux liés à sa mise à l’échelle.
Pour relever ces défis, les approches hybrides s’imposent comme une solution puissante, en combinant plusieurs techniques de détection.
Approche hybride
Dans cet article et dans le précédent, nous avons présenté un ensemble de techniques servant à détecter les images presque identiques. Chacune de ces techniques présente des forces et des limites. Par exemple, certaines négligent des aspects des images, tandis que d’autres sont très efficaces, mais coûteuses à exécuter.
L’idée derrière les approches hybrides est de combiner plusieurs techniques de détection. Autrement dit, il s’agit de tirer parti des forces de chaque méthode (et de compenser leurs faiblesses) pour créer une solution plus robuste et performante. L’approche hybride offre ainsi plusieurs avantages.
L’un des principaux avantages des approches hybrides réside dans leur précision accrue. La combinaison de techniques permet de tirer parti des atouts de chaque méthode, réduisant ainsi considérablement les faux positifs. Cette réduction des erreurs de classification est cruciale pour les fournisseurs de solutions de sécurité, car les faux positifs peuvent nuire à leur réputation et à leur crédibilité sur le marché.
La robustesse et l’adaptabilité des approches hybrides constituent un autre avantage important. En intégrant un ensemble diversifié de techniques, ces systèmes démontrent une résilience remarquable face à différentes formes de manipulation d’image. Cela permet de maintenir une détection efficace, même en présence de modifications subtiles.
Cette adaptabilité s’étend également aux stratégies d’évasions évolutives, ce qui rend les approches hybrides particulièrement adaptées au paysage dynamique des cybermenaces actuelles.
L’efficacité est un autre avantage clé des approches hybrides. Certaines techniques exigent beaucoup de ressources de calcul, mais s’avèrent très efficaces, d’autres sont plus rapides, mais peuvent compromettre un peu la précision. Cette approche permet de créer un flux stratégique qui optimise l’efficacité informatique. Par exemple, des techniques légères peuvent être utilisées pour un filtrage initial, suivies de méthodes plus intensives en ressources pour une analyse approfondie uniquement dans les cas suspects.
La souplesse des approches hybrides s’étend aux stratégies de combinaison. Il est possible d’utiliser diverses méthodes mathématiques et d’aide à la décision, notamment les règles de Pareto, le vote majoritaire et la sélection hiérarchique des algorithmes. Ces stratégies permettent une agrégation nuancée des résultats, rendant le processus de détection d’images plus fiable et plus sophistiqué.
Bien que les approches hybrides présentent aussi certains inconvénients (réglages manuels des paramètres, complexité, surcharge de traitement, etc.), une approche hybride bien conçue et correctement configurée peut offrir une solution puissante face aux défis que représente la détection d’images quasi dupliquées.
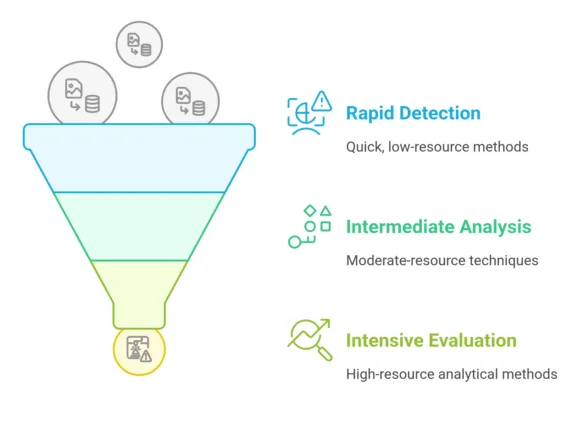
Notre système de recherche d’images inversée exploite des profils de détection hybrides, conçus de manière stratégique pour répondre à des types de menaces spécifiques. Chaque profil comprend une série de méthodes de détection sélectionnées avec soin, complétées par des techniques d’agrégation et des seuils précis pour l’identification des menaces.

Pour optimiser l’efficacité informatique, ces méthodes de détection sont mises en œuvre selon une approche en entonnoir en priorisant des techniques rapides et peu intensives en ressources, avant d’avoir recours à des méthodes analytiques plus exigeantes.
Conclusion
Dans cet article, nous avons exploré des techniques avancées de détection d’images quasi dupliquées, mettant en lumière la puissance des approches hybrides en cybersécurité. En combinant des méthodes telles qu’ORB, la reconnaissance optique de caractères (OCR) et des flux de détection stratégiques, nous avons démontré une approche sophistiquée pour l’identification des menaces visuelles.
Notre prochain article portera sur des expériences concrètes avec le système de recherche d’images inversée, afin de démontrer ses performances en conditions réelles. Nous explorerons également l’intégration de modèles multimodaux à grands volumes de langage (LLM) pour faire progresser nos capacités de détection d’images quasi dupliquées. En tirant parti des techniques d’apprentissage automatique de pointe, notre objectif est d’améliorer nos capacités à détecter les menaces visuelles grâce à des approches innovantes.


